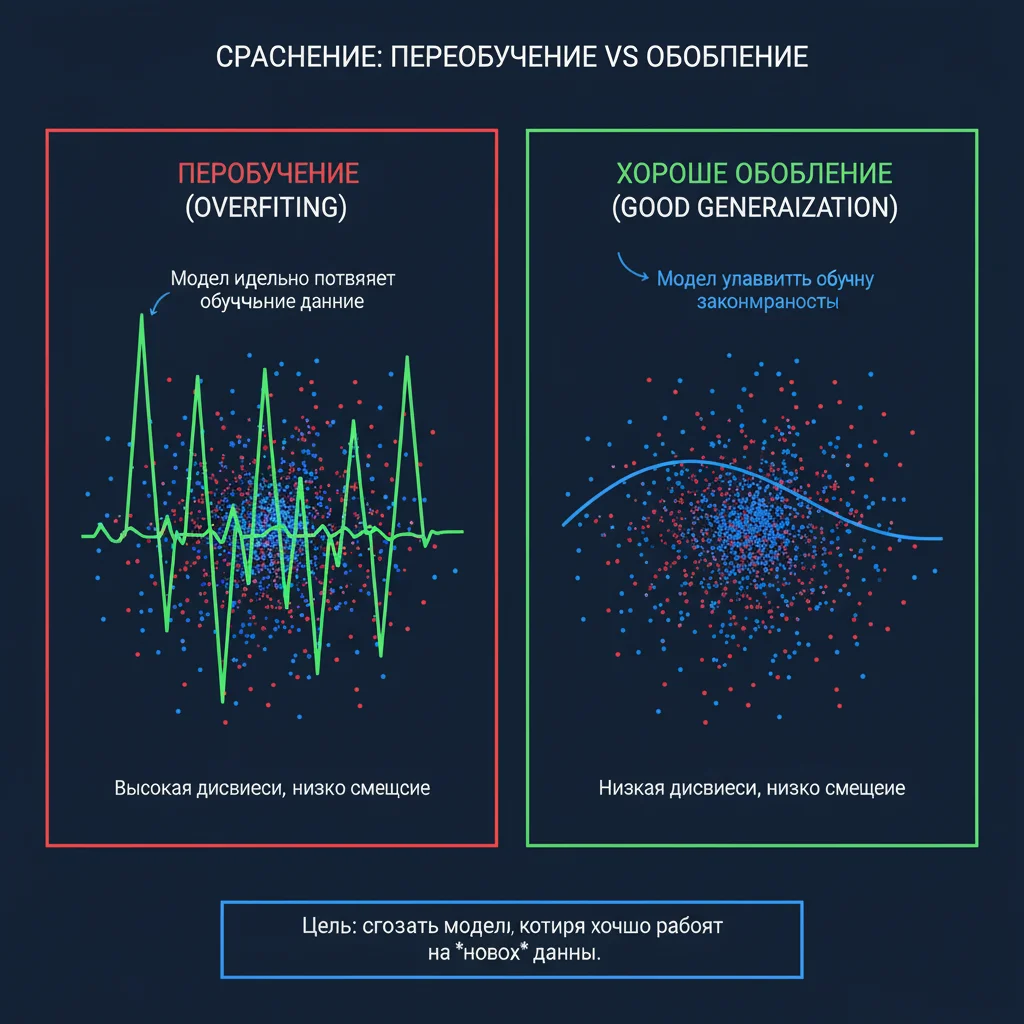
Переобучение (overfitting) — это когда нейросеть запоминает обучающие данные, включая шум и случайности, вместо того чтобы научиться обобщать. В результате она отлично работает на известных примерах, но проваливается на новых.
Как нейросети борются с переобучением:
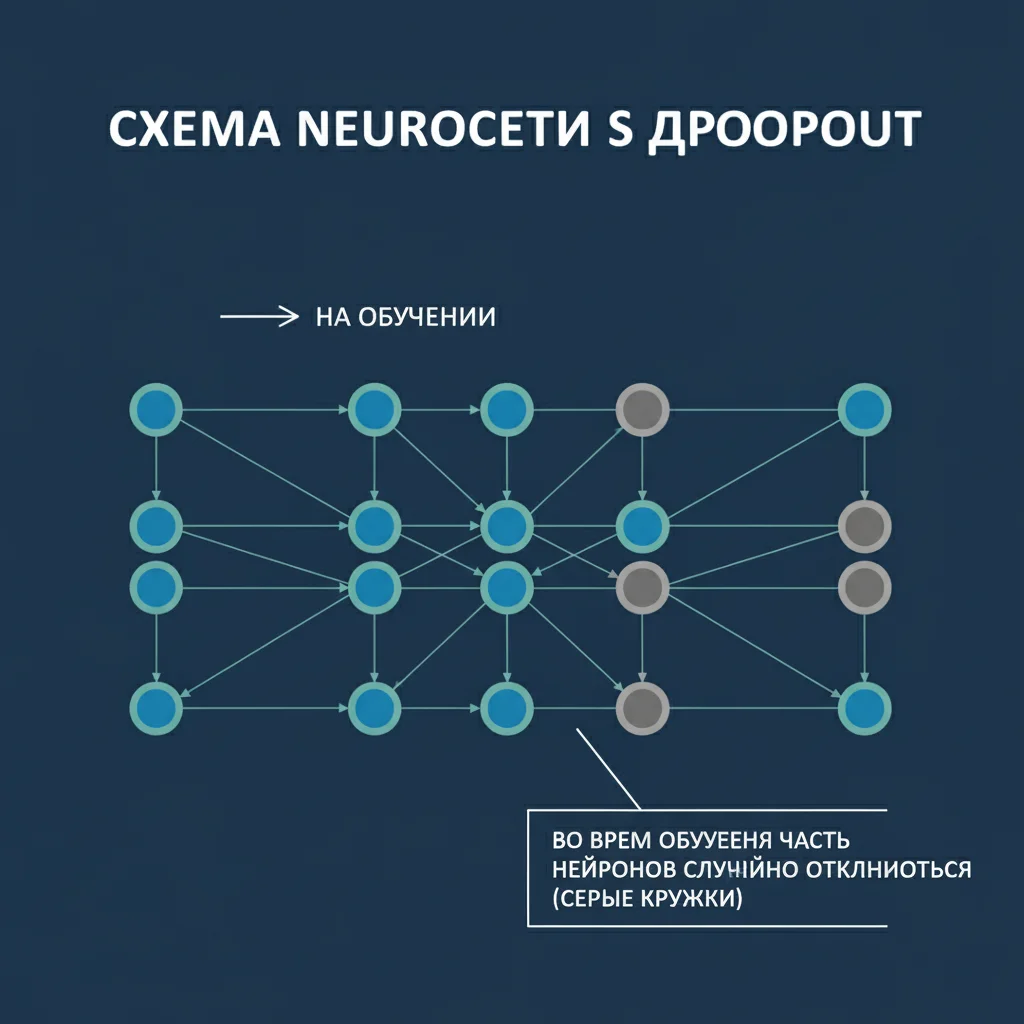
Dropout
Случайное отключение нейронов во время обучения заставляет сеть не полагаться на отдельные связи, а распределять знания.Регуляризация (L1/L2)
Штраф за слишком большие веса в сети. Это упрощает модель, делая её менее склонной к «зазубриванию».Ранняя остановка (early stopping)
Обучение прекращается, как только ошибка на валидационном наборе (не обучающем!) начинает расти — даже если на обучающем она ещё падает.Аугментация данных
Искусственное расширение набора: повороты изображений, шум в аудио, перефразировка текста. Это увеличивает разнообразие, не добавляя новых данных.Упрощение архитектуры
Иногда лучшее решение — меньше слоёв и нейронов. Простая модель часто обобщает лучше сложной.
Почему это критично:
ИИ используется в медицине, финансах, автопилотах. Если модель переобучена, она может пропустить опухоль на снимке или дать ложный сигнал о мошенничестве.
Таким образом, борьба с переобучением — это не техническая деталь, а гарантия того, что ИИ будет работать не только в лаборатории, но и в реальном мире, где всё непредсказуемо.