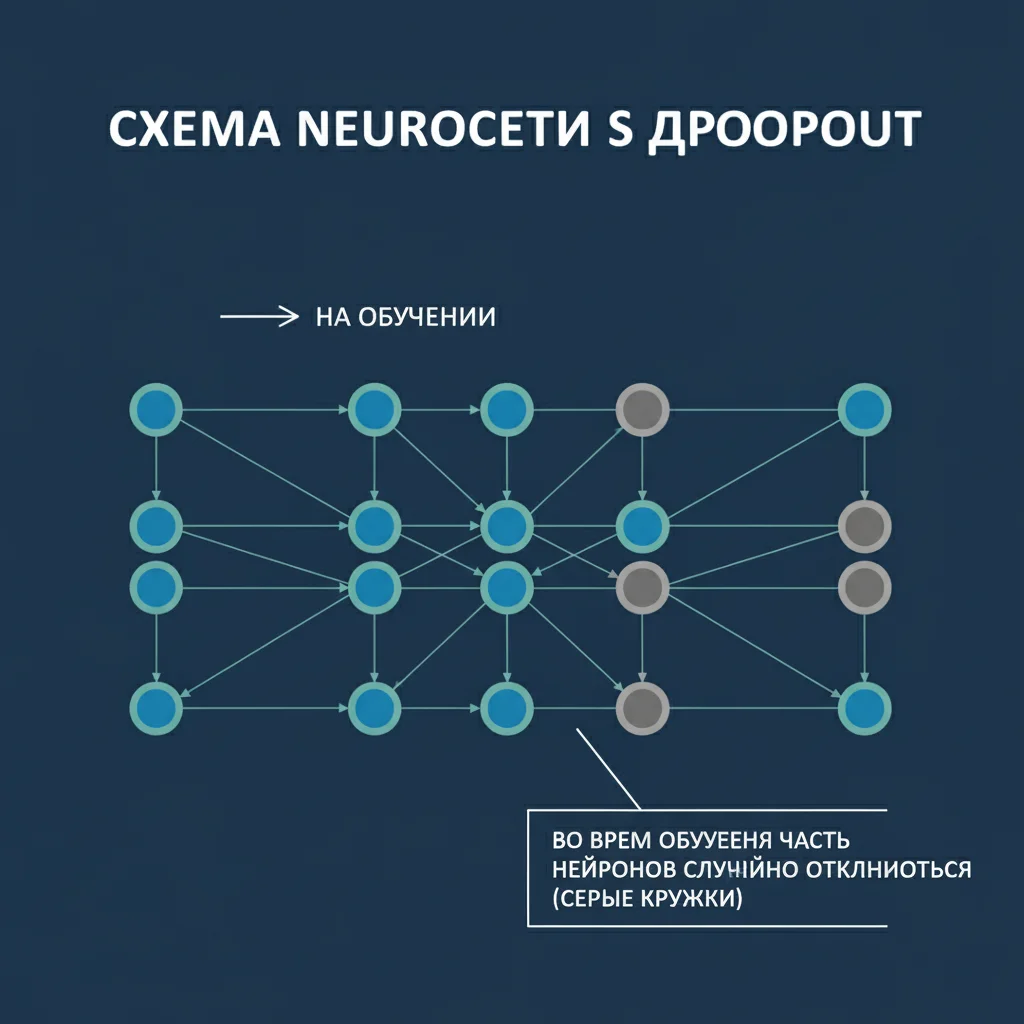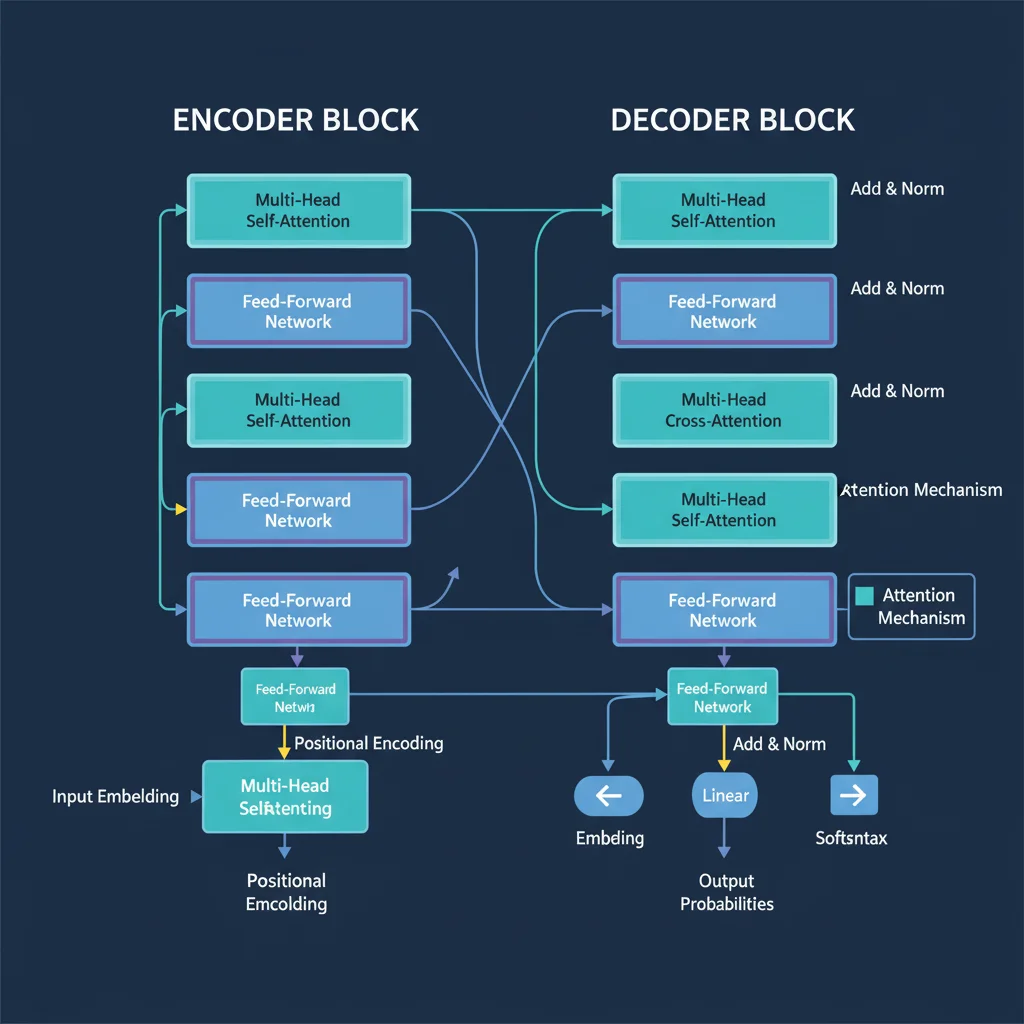
Трансформеры — это архитектура нейросетей, представленная в 2017 году в работе «Attention Is All You Need». Они полностью отказались от рекуррентных и сверточных слоёв, сделав ставку исключительно на механизм внимания (attention).
Почему они революционны:
Параллелизация
В отличие от RNN, которые обрабатывают последовательности пошагово, трансформеры обрабатывают все слова сразу. Это ускорило обучение в десятки раз.Глобальный контекст
Благодаря attention, каждое слово «видит» все остальные в предложении, независимо от расстояния. Это решило проблему «забывания» в длинных текстах.Позиционное кодирование
Поскольку трансформеры не имеют встроенной памяти о порядке, они используют позиционные эмбеддинги — векторы, добавляющие информацию о месте слова в последовательности.Масштабируемость
Архитектура легко масштабируется: чем больше данных и параметров — тем лучше результат. Это позволило создать модели с миллиардами параметров (GPT, Llama, Claude).
Где применяются:
- Языковые модели (GPT, BERT),
- Машинный перевод,
- Генерация кода,
- Анализ документов,
- Мультимодальные ИИ (текст + изображение, как в DALL·E 3).
Важно: трансформеры — не «умнее» человека. Они — мощные статистические предсказатели, но именно их архитектура сделала современный ИИ возможным.
Таким образом, трансформер — это не просто модель, а новая парадигма обработки информации, в которой внимание заменило время.