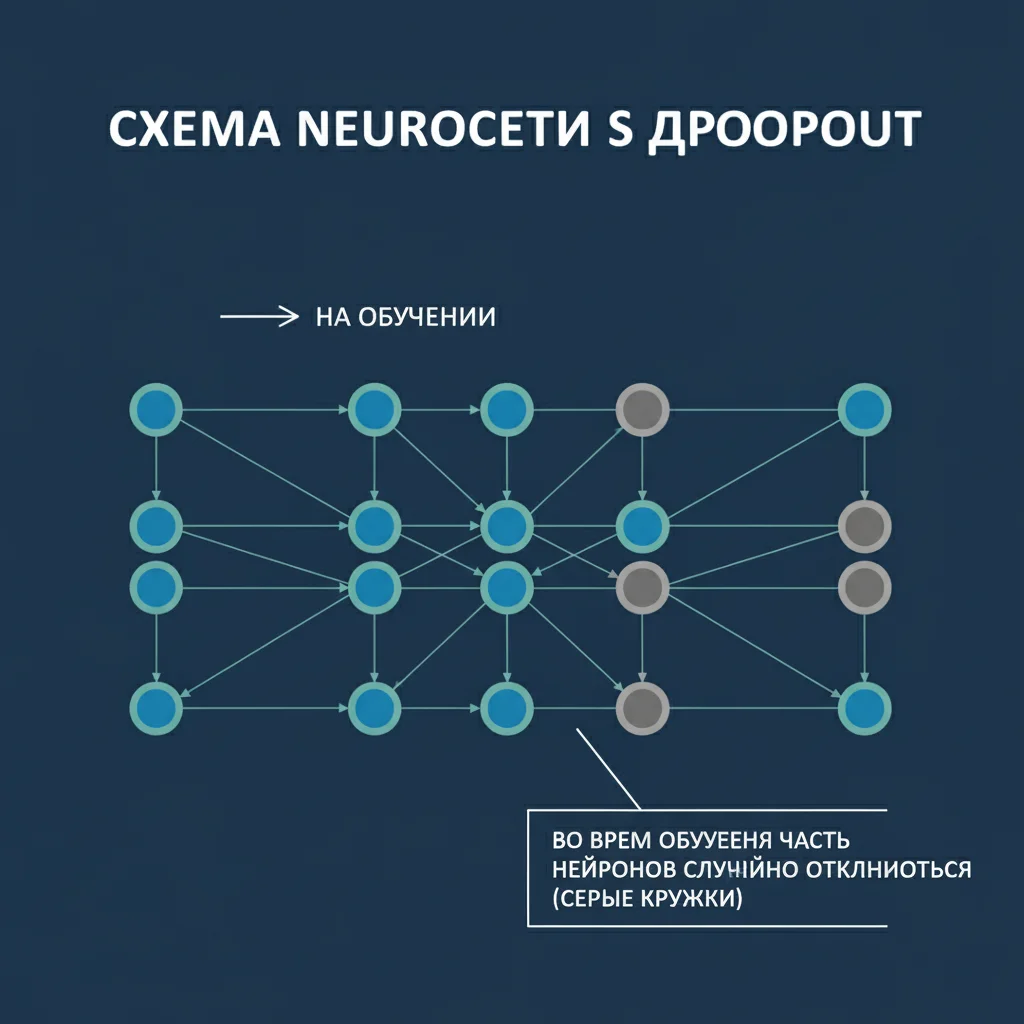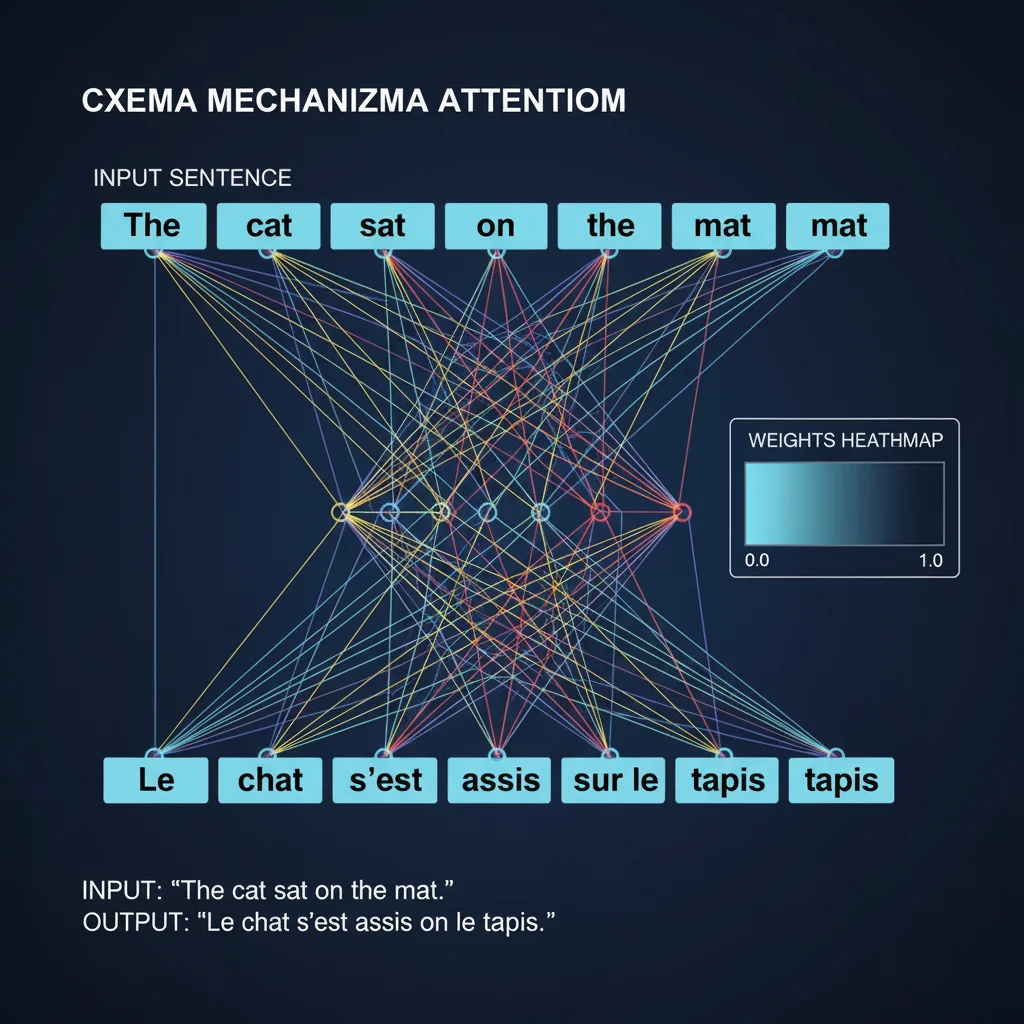
Attention-механизм («механизм внимания») — это революционный подход, позволивший нейросетям обрабатывать последовательности гораздо эффективнее, чем RNN. Он лёг в основу трансформеров и современных ИИ, таких как GPT.
Суть attention проста:
Когда сеть генерирует слово на выходе (например, при переводе), она не обрабатывает всё входное предложение одинаково. Вместо этого она взвешивает важность каждого слова во входной фразе для текущего шага.
Пример:
При переводе фразы «The cat sat on the mat» → «Кошка сидела на коврике»:
- При генерации слова «кошка» сеть делает наибольший акцент на «cat»,
- При генерации «коврике» — на «mat».
Как это работает технически (без формул):
- Каждое слово преобразуется в вектор (embedding),
- Сеть вычисляет «схожесть» между вектором текущего выходного слова и всеми входными,
- На основе этой схожести строится взвешенная сумма — «контекстный вектор»,
- Этот вектор используется для генерации следующего слова.
Почему это важно:
- Устраняет проблему «забывания» в длинных последовательностях (у RNN),
- Позволяет параллельную обработку — обучение стало в разы быстрее,
- Даёт интерпретируемость: можно визуализировать, на что «смотрела» сеть.
Таким образом, attention — это имитация человеческого внимания: не всё одинаково важно, и мудрость — в умении фокусироваться на главном.