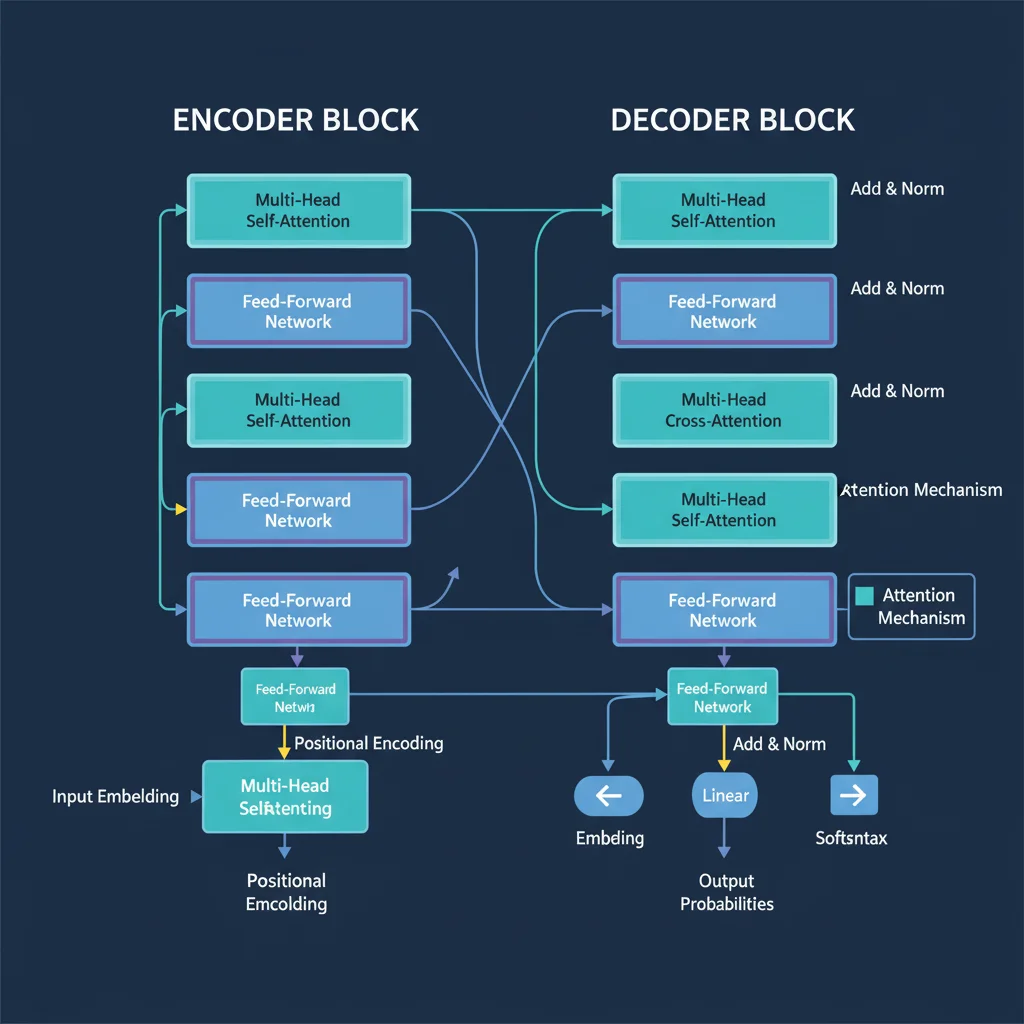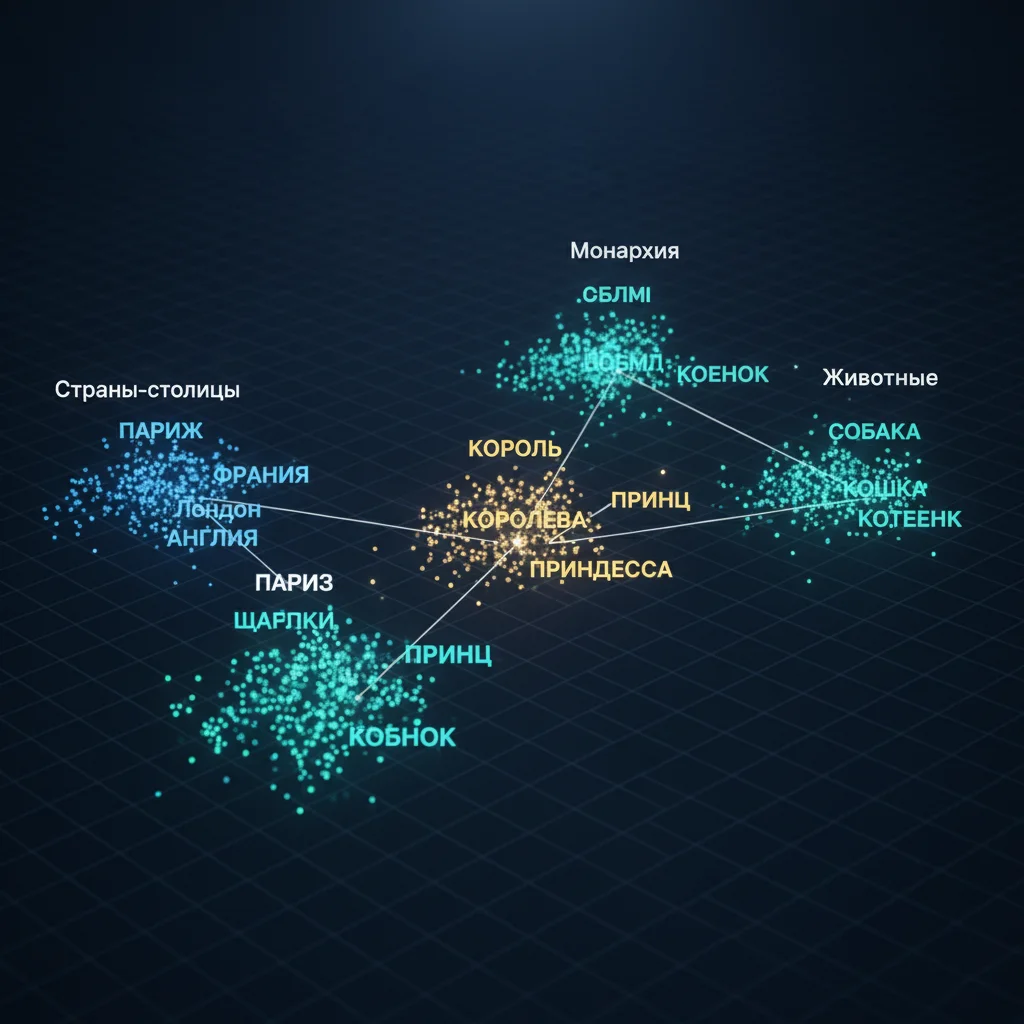
Embedding-пространство — это многомерное математическое пространство, в котором каждое слово представлено как точка (вектор). Близость точек отражает семантическую близость: чем ближе слова по смыслу, тем ближе их векторы.
Как это работает:
Обучение через контекст
Нейросеть анализирует миллиарды предложений и учится:- Слова, которые часто появляются в похожих контекстах, получают похожие векторы,
- Например, «кот» и «собака» будут ближе друг к другу, чем «кот» и «автомобиль».
Арифметика смыслов
В embedding-пространстве работают удивительные закономерности:- «Король» – «мужчина» + «женщина» ≈ «королева»,
- «Париж» – «Франция» + «Италия» ≈ «Рим».
Это показывает, что модель улавливает абстрактные отношения между понятиями.
Не только слова, но и фразы
Современные модели (вроде BERT) создают контекстно-зависимые embedding:- «Свет» в «включи свет» и «свет надежды» будут иметь разные векторы.
Почему это важно:
- Embedding позволяет ИИ оперировать смыслом, а не просто совпадением слов,
- Это основа для поиска, перевода, классификации текста и генерации,
- Без embedding языковые модели были бы глухи к смыслу.
Интересно:
- Пространство может иметь сотни или тысячи измерений — гораздо больше, чем мы можем визуализировать,
- Некоторые измерения соответствуют конкретным признакам: гендер, время, эмоциональная окраска.
Таким образом, embedding — это язык смысла, на котором нейросети «думают» о словах. И хотя это всего лишь математика, она удивительно близка к тому, как устроено наше собственное мышление.