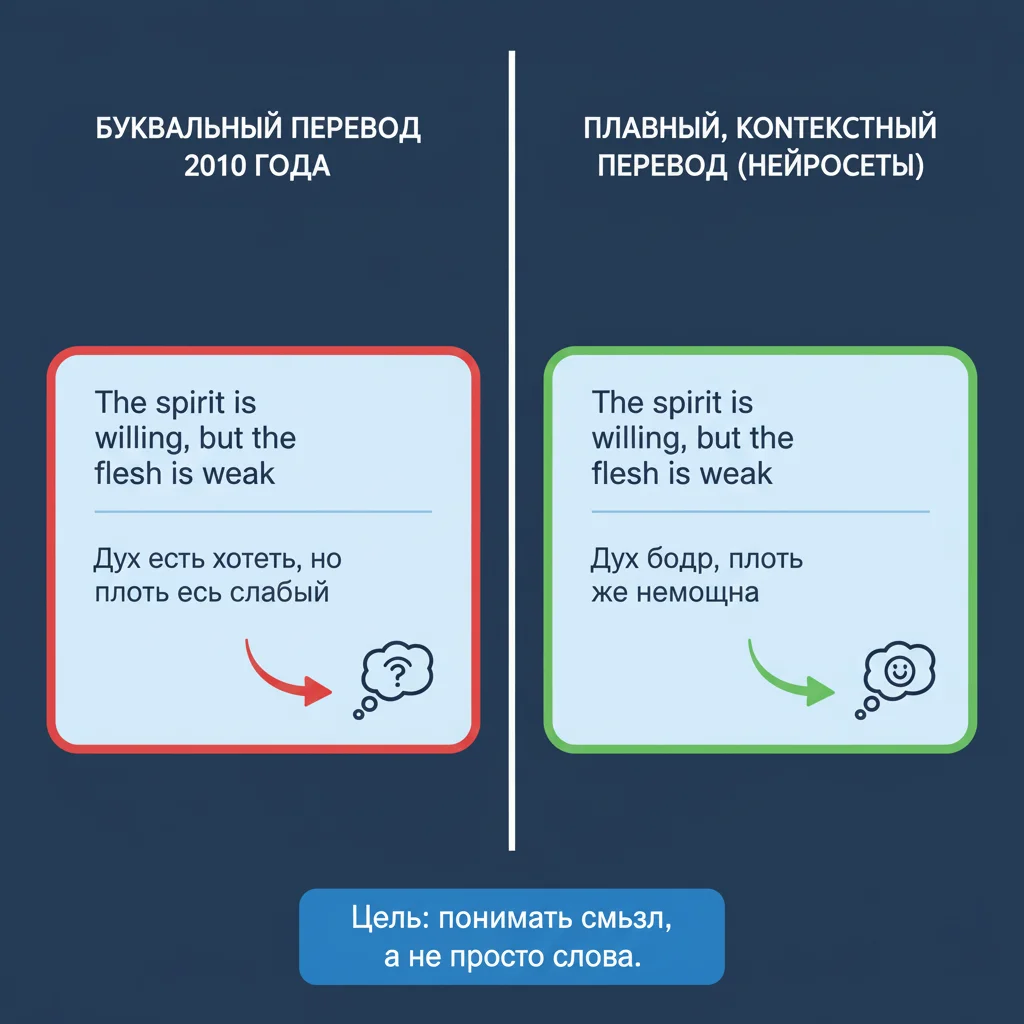
Ранние переводчики (вроде Google Translate до 2016 года) использовали статистический машинный перевод (SMT): переводили по фразам, без понимания смысла. Результат часто был корявым и бессмысленным.
С появлением нейросетевого машинного перевода (NMT) всё изменилось.
Как работает современный перевод:
Единая нейросеть вместо частей
Вся фраза обрабатывается целиком, а не по кусочкам. Это позволяет учитывать контекст:- «Bank» → «банк» или «берег» — в зависимости от предложения.
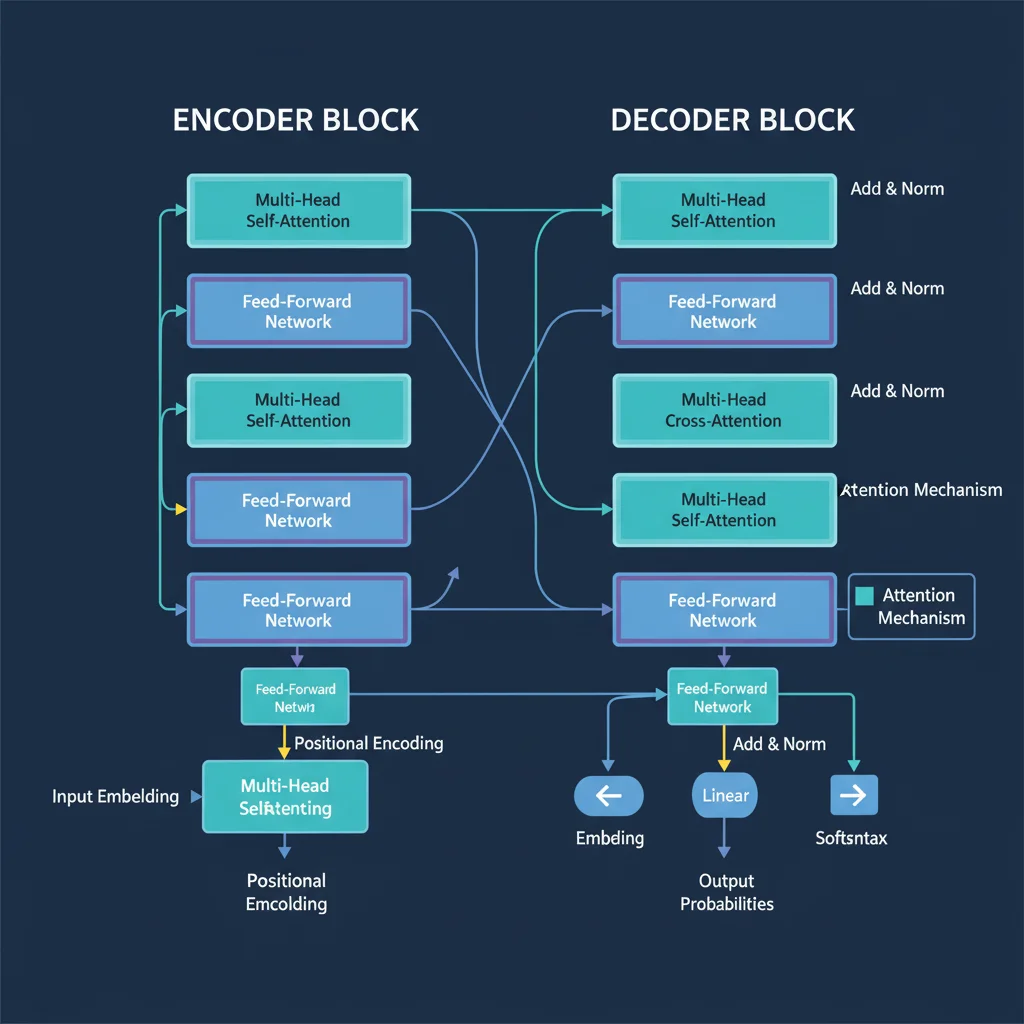
Encoder-Decoder архитектура
- Encoder превращает исходный текст в «смысловой вектор»,
- Decoder генерирует перевод на целевом языке, сохраняя структуру и оттенки.
Attention-механизм
Сеть «внимательно читает» исходный текст, фокусируясь на наиболее релевантных словах для каждого шага перевода.Обучение на параллельных корпусах
Модели обучаются на миллионах пар предложений (например, официальные документы ООН на 6 языках).
Результаты:
- Перевод стал плавным, грамматически правильным, идиоматичным,
- Поддержка редких языков (свази, маори) благодаря zero-shot переводу,
- Сохранение тона и стиля: формальный, дружеский, поэтический.
Примеры:
- Google Translate, DeepL, Yandex Translate — все используют NMT,
- DeepL особенно силён в европейских языках благодаря качественным данным.
Ограничения:
- Может «галлюцинировать» при сложных текстах,
- Не всегда передаёт культурные нюансы,
- Требует огромных данных для редких языков.
Тем не менее, нейросетевой перевод — это один из самых зрелых и полезных ИИ-инструментов, стирающий языковые барьеры для миллионов людей каждый день.