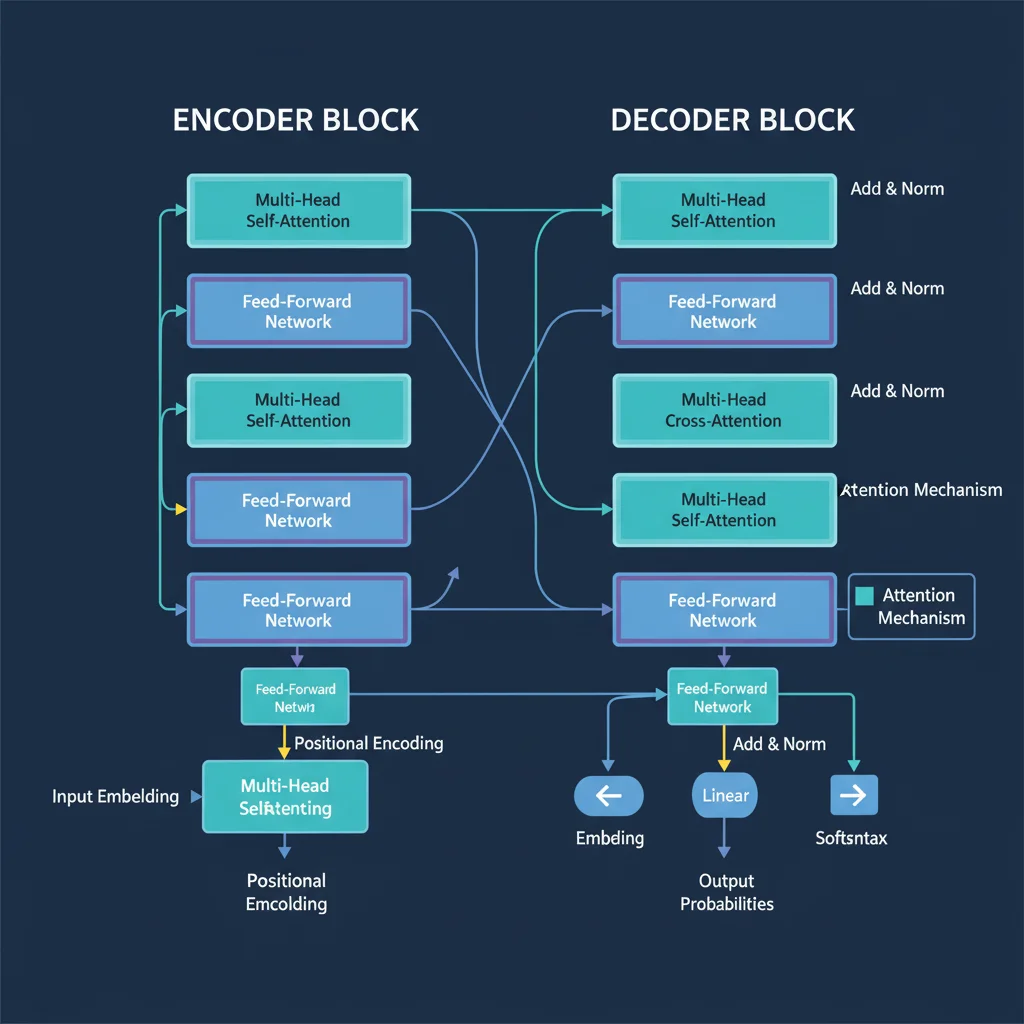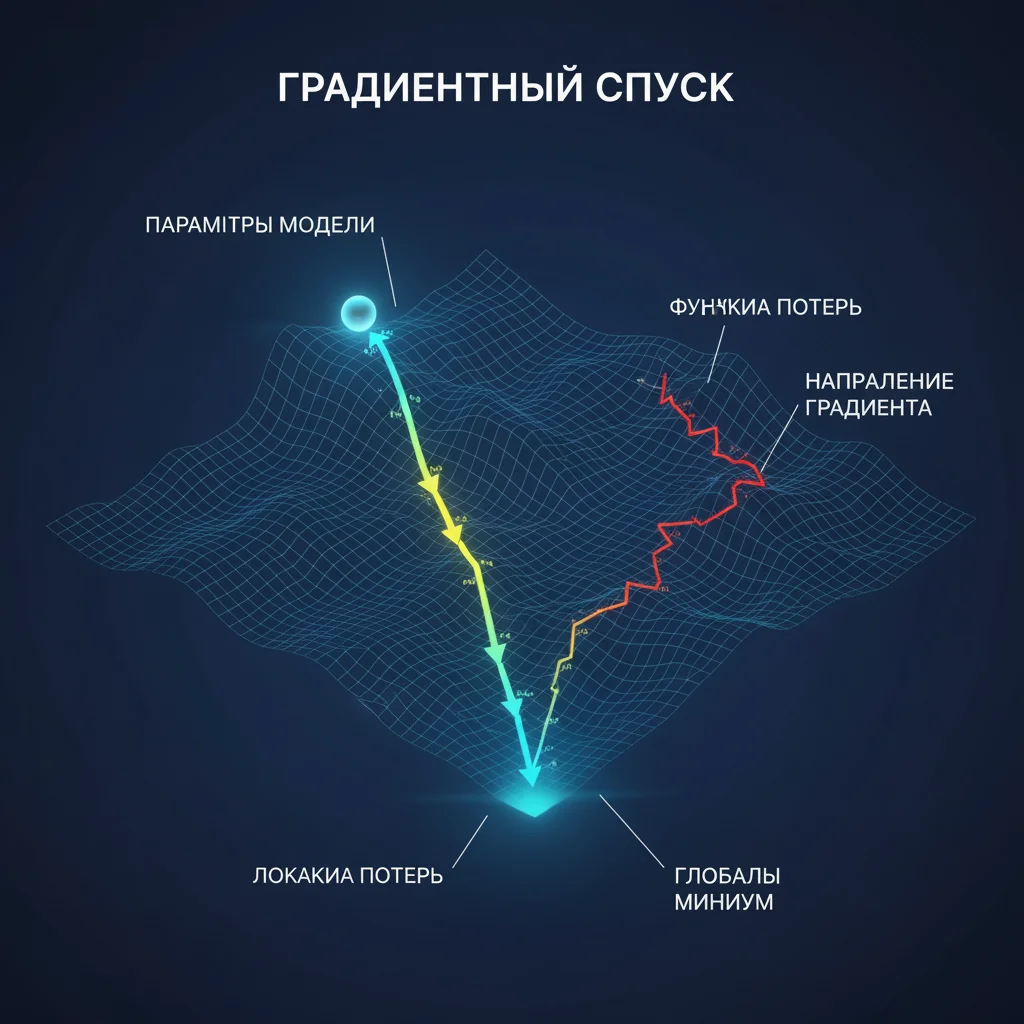
Градиентный спуск — это алгоритм оптимизации, лежащий в основе обучения нейросетей. Его цель — найти такие значения весов, при которых ошибка сети минимальна.
Как это работает (на аналогии):
Представьте, что вы стоите на склоне холма в густом тумане. Вы не видите дна, но чувствуете, в какую сторону идти вниз. Вы делаете маленький шаг в самом крутом направлении вниз. Повторяете. Со временем вы достигаете самой низкой точки — минимума функции ошибки.
В терминах нейросети:
- Холм = функция потерь (ошибка),
- Позиция на склоне = текущие значения весов,
- Направление вниз = градиент (вектор, показывающий, как изменить веса, чтобы уменьшить ошибку),
- Длина шага = скорость обучения (learning rate).
Важные нюансы:
- Если шаги слишком большие — вы «перешагнёте» минимум и будете скакать вокруг,
- Если слишком маленькие — обучение займёт вечность,
- Иногда алгоритм застревает в «ложбине» (локальном минимуме), но в высоких измерениях это редкость.
Современные версии (Adam, RMSprop) адаптируют размер шага автоматически, делая обучение быстрее и стабильнее.
Таким образом, градиентный спуск — это метод проб и ошибок, ускоренный математикой. Он не гарантирует идеального решения, но почти всегда находит достаточно хорошее — и делает это миллионы раз в секунду.