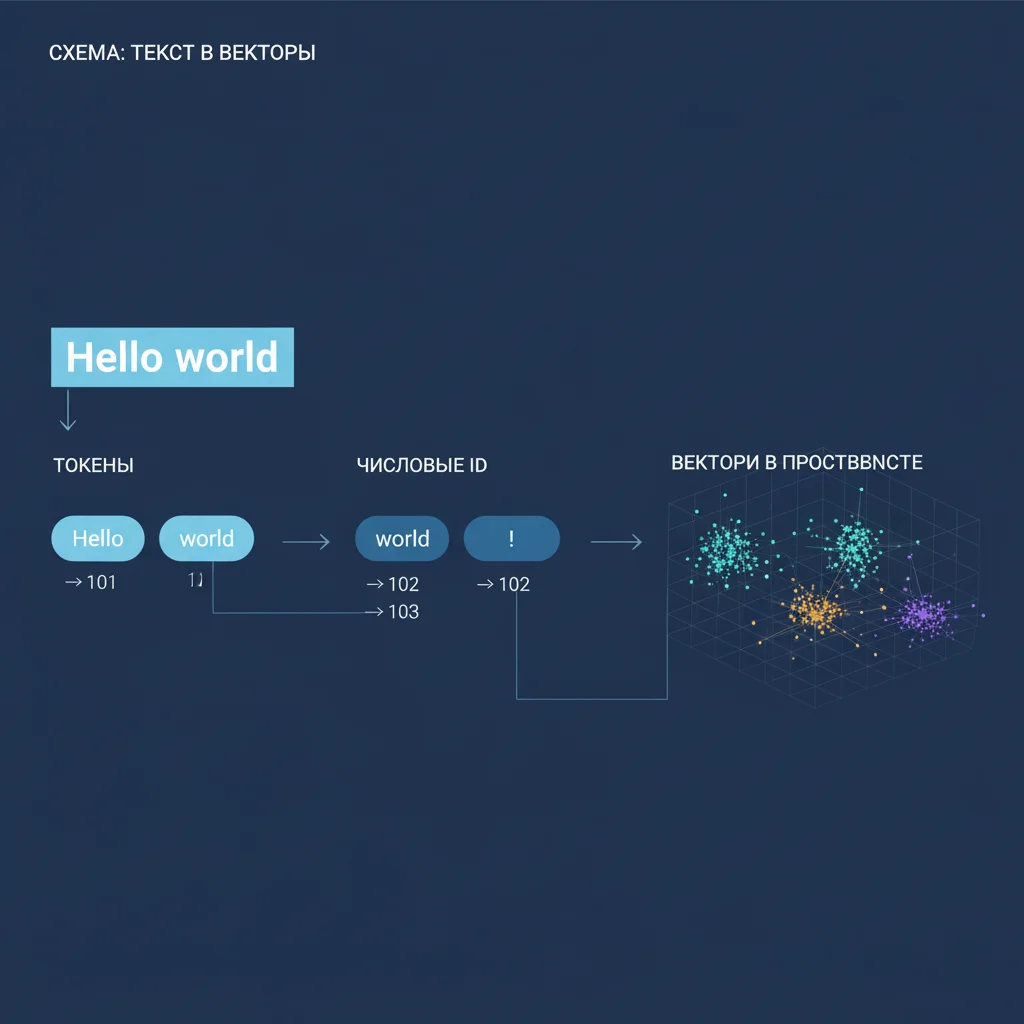
Токенизация — это процесс разбиения текста на единицы, которые нейросеть может обрабатывать. Поскольку ИИ «понимает» только числа, каждое слово (или его часть) должно быть преобразовано в цифровой код.
Как это происходит:
Разбиение на токены
Токен — это не всегда слово. Это может быть:- Слово целиком («кошка»),
- Подслово («кош» + «ка»),
- Символ («@», «.»).
Современные модели (например, BPE — Byte Pair Encoding) используют подсловные токены, чтобы справляться с редкими и новыми словами (вроде «нейросеть» или «мем»).
Преобразование в ID
Каждый токен получает уникальный номер из словаря модели (часто 30 000–100 000 элементов). Например:- «Привет» → 1245,
- «мир» → 3092.
Преобразование в вектор
Числовой ID подаётся в embedding-слой — таблицу, где каждому ID соответствует вектор (например, 768 чисел). Этот вектор кодирует смысл и контекст слова.
Почему это важно:
- Подсловная токенизация позволяет модели работать с любыми языками и неологизмами,
- Векторы позволяют ИИ «понимать», что «кот» ближе к «собаке», чем к «автомобилю»,
- Без токенизации языковые модели просто не могли бы существовать.
Интересно:
- В русском языке из-за богатой морфологии особенно важна подсловная токенизация,
- Один и тот же токен может иметь разные векторы в зависимости от контекста (благодаря attention).
Таким образом, токенизация — это мост между человеческим языком и машинной логикой. Именно с неё начинается «понимание» текста ИИ.